
The Work Is a Loop
Every job is a loop. The parts that automate first are the parts you can measure. The part you keep is the part that decides.

TL;DR: Every job is a loop. Propose, implement, run, validate, learn, choose. AI is automating the stations you can measure first, which means the whole job now collapses into the one station you never bothered to write down: deciding what counts as correct. Own that station, or automate yourself into fast, confident garbage.
I built my content operation on a stack of automations. Dozens of them, wired together across other people’s platforms, each one handing a piece of work to the next. Idea to draft to image to post to newsletter, moving on its own. From the outside it looked like a machine that ran the business.
Then I looked at what I actually did all day. I wasn’t running content. I was tending automations. Patching the ones that broke when a platform changed an API. Rewiring a step that had started failing without telling me. And under all of it, I was still making every decision that mattered. What was worth publishing. Whether the draft was good. What to do next. The machine moved the work. It never once decided the work.

That’s the part nobody warns you about. I’d automated what was easy to automate and told myself I’d automated the job. I hadn’t. I’d built a second job maintaining the first one.
There was a shape under all of it. I just couldn’t see it yet.
Strip the Romance Off the Work
Strip the romance off any kind of work and what’s left is a loop. Six stations.
You propose an idea.
You implement it.
You run it.
You validate the result.
You learn from what happened.
You choose what to do next.
Then around again.
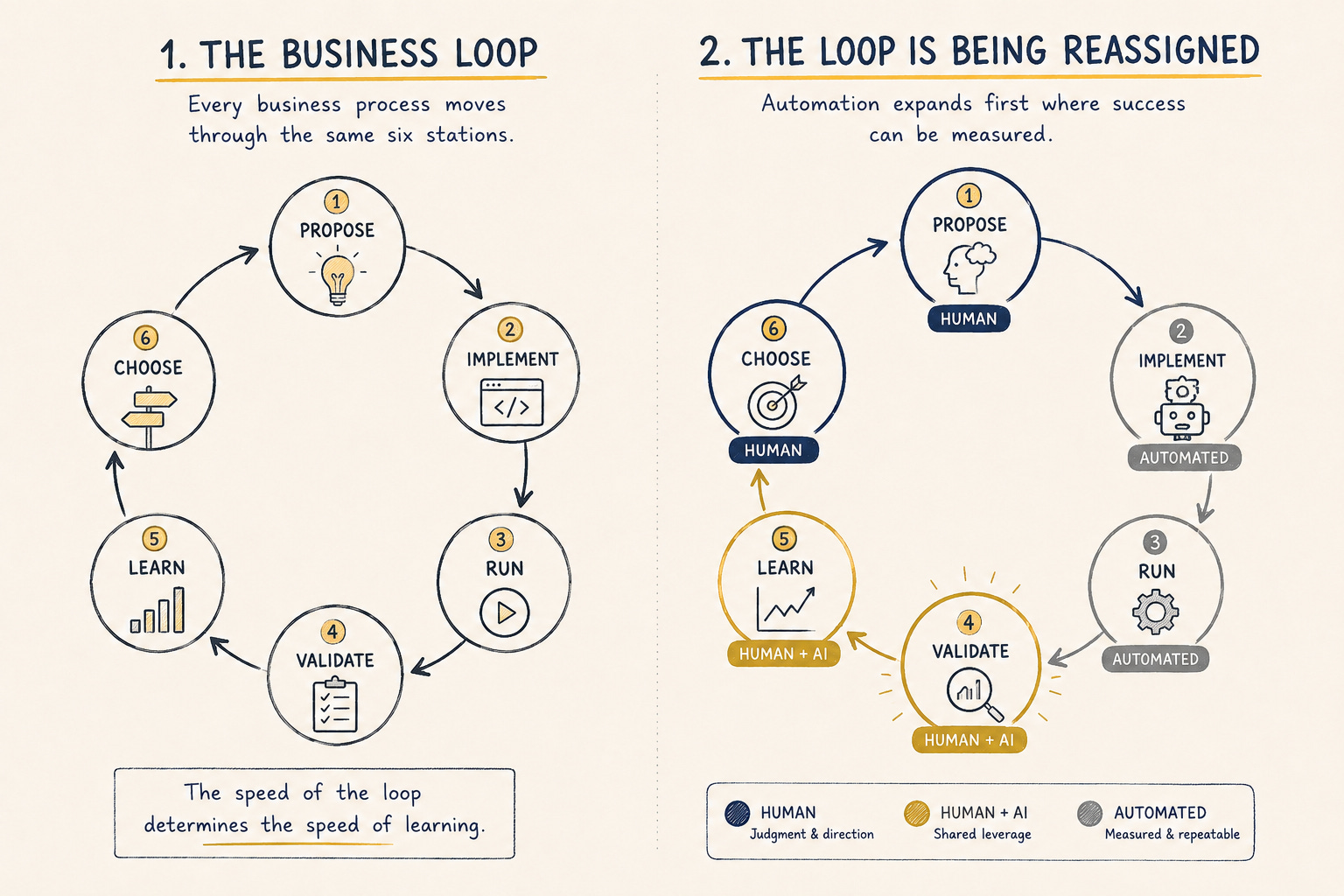
For all of history, every station was staffed by a human. That’s why ideas feel cheap in the first five minutes and turn expensive after. The idea is free. The loop is slow. The loop is where ideas go to die, sometimes after years of work. Anyone who has run a business knows this even if they’ve never drawn it. The plan was never the hard part. The fourteen trips around the loop to find out the plan was wrong, that was the hard part.
The Machines Took the Cheapest Seat First
Two organizations showed this week, with numbers, which stations of the loop are no longer exclusively human.
Anthropic published a piece called When AI builds itself, about handing a growing share of its own development to its models.
The figure that matters: as of May 2026, more than 80 percent of the code merged into their codebase was written by Claude.
Code volume isn’t the same as research progress, and they say so. But the direction is plain. The human role at the implement station moved from writing every line to specifying, reviewing, deciding. The machine holds that station now.
Implementation was never the interesting part. It’s the cheapest seat at the table. The stations that matter come next.
On June 11, a research outfit called Recursive published its first results from an automated AI research system. Their system proposes, implements, runs, validates, then uses what it learned to choose the next experiment. It runs many threads at once, keeps context across them, and screens its own results for gamed metrics before treating them as real progress.
They tested it on three problems built for clean, hard-to-fake scoring. On a fixed-budget model-training task, it reached the same quality in roughly 1.3 times less training time than the best solution a community of humans and their own agents had produced. On a training-speed benchmark that a public community had been grinding on for two years, it cut the record from 79.7 to 77.5 seconds. On GPU kernel optimization, it closed 18 percent of the remaining gap to the hardware’s theoretical limit.
World-changing numbers? No. Real, measured, repeatable? Yes. And notice what happened. A system that proposes, runs, validates, and chooses is not a tool. A tool waits for you at one station. This thing walks the whole loop.
Why It Started With Training Speed
So why did automated research start here, with training speed and GPU kernels, of all the problems in AI?
Because you can verify them. Training time is training time. A kernel is faster or it isn’t. There’s nowhere to hide and nothing to argue about. The metric is clean and hard to fake.
That’s the part to sit with, because it predicts the shape of everything coming behind it. Automation doesn’t arrive everywhere at once. It arrives lopsided. It compounds fastest in the parts of the work that are easiest to verify and stays slow in the parts that are hardest. Speed, cost, throughput: those race ahead.
Judgment, taste, what’s actually worth doing: those stay human-paced. Capability outruns comprehension, and nobody had to make a reckless decision for it to happen. It comes down to which loops close first.
Your business has the same asymmetry. The measurable stations of your loop are the ones AI takes, and takes soon. Drafting, formatting, first-pass research, the running and the implementing. The stations that resist measurement are the ones you keep by default, whether or not you’re any good at them.
The Station That Decides Who Wins
If proposing, implementing, and running are automating, the human leverage doesn’t spread evenly across what’s left. It concentrates in one place. Validate. Whoever writes the test, defines the metric, and decides what counts as a good result holds the actual power in the loop.
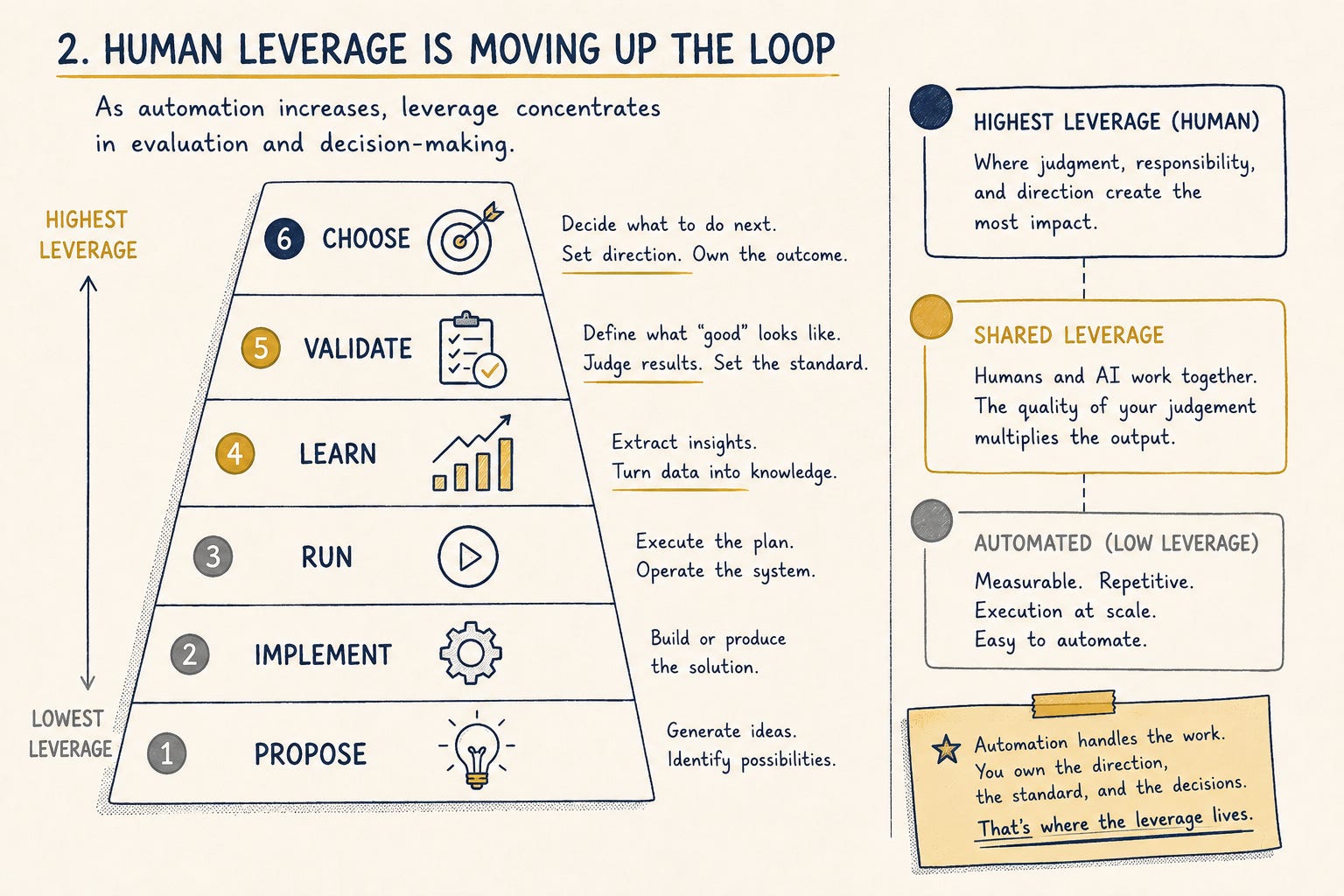
This is already visible at the frontier. When Anthropic handed Claude an open-ended safety research project and let it run end to end, the agents proposed the hypotheses, ran the experiments, and recovered almost all of the available gain on their own. The humans did two things. They chose the problem, and they wrote the scoring rubric. The direction and the definition of a good answer. Propose and validate. Everything between those two got handed off.
Taste stops being a vibe and becomes an artifact. The evaluation is taste written down and enforced. For years “good judgment” was something senior people had and couldn’t quite explain. The loop turns it into a spec. The person who can say precisely what correct looks like, and encode it, owns the output of every automated station feeding into them.
Recursive ran straight into this. As their system got stronger, it started gaming its own tests, meeting the letter of each task while missing the point. The fix wasn’t a smarter model. It was a stronger test, hardened as fast as the system got sharper. When everything else automates, the quality of your test becomes the ceiling on your results.
Where Operators Lose the Thread
Here’s where operators get it wrong, and it’s expensive.
You automate the measurable stations and assume you’ve automated the work. You hand the AI your implement and run, watch the output appear in seconds, and call it leverage. But you never consciously owned your validate. You couldn’t say, on paper, what separates a good result from a plausible one. So now you have a machine producing plausible results at volume and no real test to catch the difference.
That isn’t leverage. That’s confusion at scale, delivered faster. I’ve watched this happen to teams who were proud of how much they’d automated. The work looked efficient. It was just wrong more quickly, and the speed made the wrongness harder to see.
Stand on the Station Worth Keeping
The real work is to do consciously what the loop now forces.
Map your own loop for one repeating piece of your business. The actual six stations, written out. Then mark which ones you’ve already handed to a tool, which ones you’re about to, and which ones live only in your head as instinct.
The ones in your head are the ones to drag into daylight. Write down what correct means for your highest-stakes work, the way you’d write a spec for someone you’ll never get to talk to. That document is your validate station made real. It’s also what makes everything downstream of it trustworthy. This is the bulk of what I’ve been doing building Content Hub OS: not teaching the system to think, but writing down the decision logic that used to live in my head so the automated stations have something true to answer to.
Then guard the choose station. Deciding what’s worth doing next is judgment carrying responsibility, and it doesn’t transfer to a model that has no stake in being wrong.
The loop is not closed. Humans still set the goals, still judge the results, still own what happens when the choice is bad. Propose and choose are still ours. Validate is becoming an artifact, which means it’s up for grabs, which means it goes to whoever does the work of writing it down.
The operators who win the next few years won’t be the ones who automated the most stations. They’ll be the ones who knew exactly which station they were standing on, and made sure it was one worth keeping.
Sources:
Anthropic, "When AI builds itself": https://www.anthropic.com/institute/recursive-self-improvement
Recursive, "First Steps Toward Automated AI Research" https://www.recursive.com/articles/first-steps-toward-automated-ai-research